
Googlebot is the backbone of Google’s search engine ecosystem. It’s more than just a program that “visits websites”; Googlebot actively interprets, prioritizes, and serves content to users based on relevance, quality, and accessibility.
But why should SEO experts, content strategists, and business owners care about understanding Googlebot?
Knowing how it evaluates your website can mean the difference between ranking on the first page or getting buried. Google’s focus on E-E-A-T (Experience, Expertise, Authority, Trustworthiness) means aligning your content with what Googlebot is designed to prioritize.
Here’s what this guide will cover:
- What Googlebot is and how it influences rankings
- How Googlebot chooses what to crawl and when
- Ways to optimize your site to get the most from Googlebot’s visits
Let’s dive right in!
What is Googlebot?
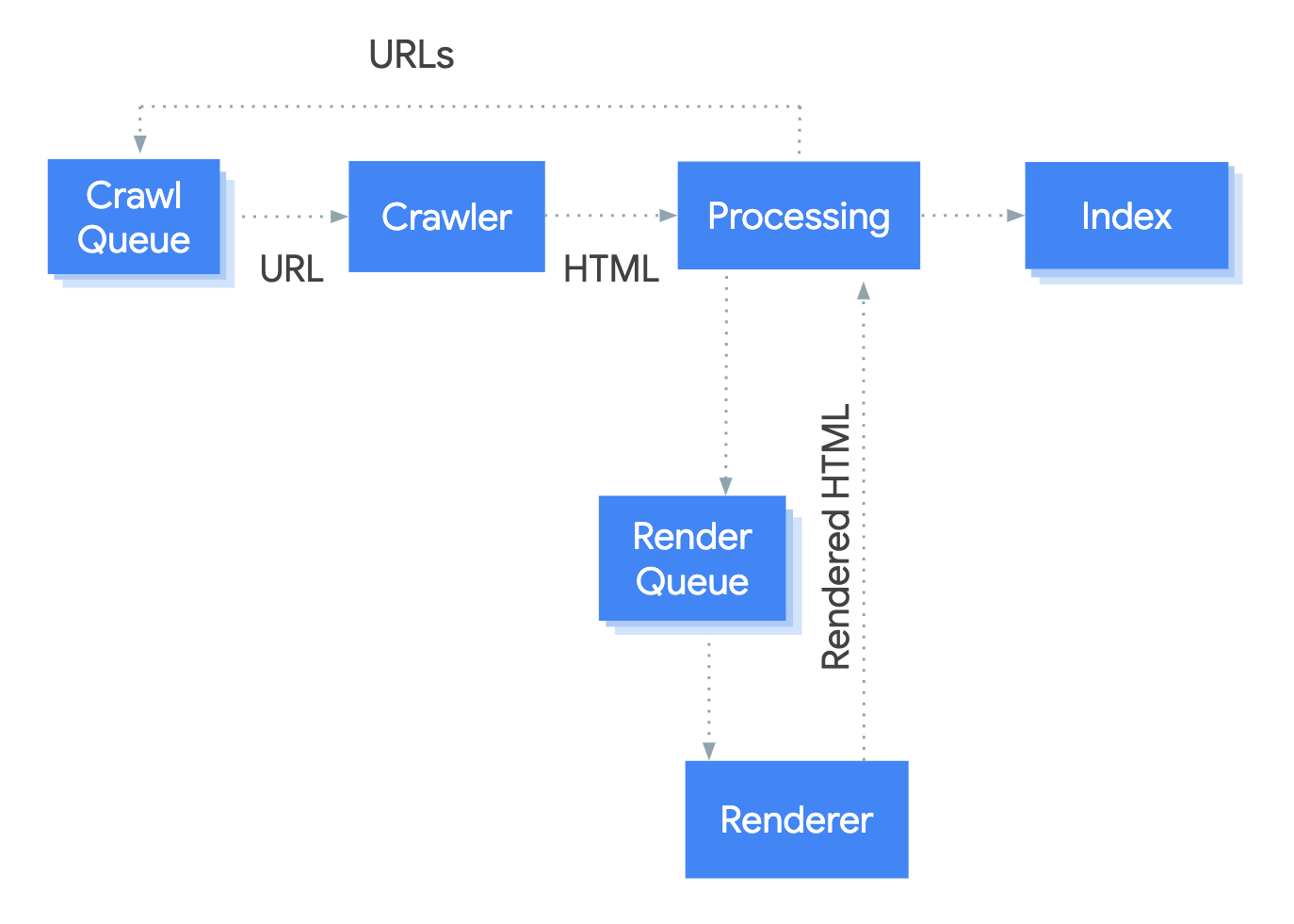
Googlebot is essentially Google’s automated program that crawls the web to find new pages and updates. It’s a crawler, or spider, that systematically browses the web, gathering information to build Google’s index.
Why does this matter?
Googlebot is the first line of interaction between your website and Google’s search algorithm. Every URL it visits, every piece of content it interprets, and every link it follows contributes to Google’s understanding of the web.
Key Technical Components of Googlebot
Crawling: Googlebot’s first step is to locate new or updated pages. This process involves identifying links within your website and from other sources.
Indexing: After crawling, Googlebot stores data about the pages it visited, organizing it in a way that Google can retrieve quickly during search queries.
Serving Results: When a user types in a query, Google’s algorithm determines which pages to display from the indexed data, factoring in relevancy, quality, and user experience.
How Googlebot Works: A Step-by-Step Process
To master SEO, it’s crucial to understand each phase of Googlebot’s operation. Each step is influenced by algorithms, user behavior data, and your site’s structure.
Crawling: Googlebot uses two main methods for crawling—URL discovery and link-following. Each time a new URL is published, Googlebot follows links to locate it. Pages with strong internal linking structures and relevant external links are more likely to be crawled and updated frequently.
- Ensure internal links connect high-value pages for better crawl efficiency. Adding an XML sitemap also aids in prioritizing specific pages, ensuring Googlebot covers all critical content.
Indexing: Once Googlebot crawls a page, it evaluates content quality, structure, and relevance. Pages that are well-structured and contain semantic relevance (keywords, phrases, and related concepts) are prioritized.
Serving Results: The indexing process doesn’t guarantee visibility. Google’s algorithms decide the most relevant pages to show based on user intent, ranking factors, and content quality.
Types of Googlebot Crawlers
Googlebot comes in different versions, each designed to simulate how users access content across various devices.
Types of Googlebot Crawlers:
- Desktop Crawler: Mimics a user visiting from a desktop device. While not the primary crawler today, it’s still important for websites with high desktop traffic.
- Mobile Crawler: Google’s primary crawler since the introduction of mobile-first indexing. It views content as a mobile user would, meaning mobile-friendly design is essential for high-ranking potential.
Did you know?
63% of Google searches are conducted on mobile devices, underscoring the importance of mobile-first optimization for SEO success.
Pro Tip: Evaluate your website’s mobile usability through Mobile-Friendly Test tool. This ensures that Googlebot encounters no issues when crawling mobile versions, which can positively impact rankings.
How Googlebot Chooses What and When to Crawl
Googlebot doesn’t crawl every page on the web equally; instead, it prioritizes based on several factors:
- Content Popularity: Frequently updated, high-traffic sites attract more frequent crawls.
- Relevance and Freshness: Googlebot often revisits pages with recent updates or timely information.
- Internal and External Links: Websites with strong, relevant internal linking and quality backlinks tend to be crawled more often.
- Crawl Budget: Google allocates a specific amount of “crawl budget” per site, based on the site’s importance, size, and update frequency.
Managing crawl budgets is crucial. Avoid cluttering your site with low-value pages or duplicate content, as this can waste crawl budget and reduce Googlebot’s attention to important pages.
Advanced Tip: Suggest adding high-quality, relevant backlinks and using internal linking to drive Googlebot’s attention to valuable content. Recommend tools like Screaming Frog to analyze link structures and optimize crawl efficiency.
Monitor Googlebot Activity on Your Site
Tracking Googlebot’s behavior on your site can reveal how well it’s crawling and indexing your pages. Monitoring tools like Google Search Console and server log analyzers are critical for understanding crawl patterns.
Google Search Console: Provides insights into crawl errors, indexing status, and overall crawl activity.
Server Logs: By analyzing server logs, you can see which pages Googlebot crawls, how often, and detect any crawl errors or anomalies.
- What to Look For: Focus on pages with high-value keywords and user engagement to ensure they’re being crawled regularly.
- Quick Troubleshooting: If certain pages are ignored, ensure they’re linked from high-traffic pages and included in the XML sitemap.
Recommend a monthly server log analysis to keep track of crawl patterns and promptly address any issues. This can be crucial for large websites with extensive content.
Controlling Googlebot
Taking control over what Googlebot crawls can drastically improve site performance.
Here’s how:
- Robots.txt File: Use robots.txt to block irrelevant or sensitive pages from being crawled (e.g., admin pages).
- Meta Tags (Noindex, Nofollow): Implement noindex tags on low-value pages to prevent them from cluttering the index.
Avoid using robots.txt to block high-value pages. Misconfiguring it can lead to accidental ranking losses or deindexing of critical pages.
Example: Include a short example of a well-configured robots.txt file to demonstrate best practices and avoid common pitfalls.
Googlebot and JavaScript
JavaScript can be a challenge for crawlers if not implemented properly. As websites increasingly rely on dynamic content, it’s crucial to make sure Googlebot can access it.
- Problem with JavaScript: If improperly configured, JavaScript content may not render fully, causing Googlebot to miss important information.
- Solution: Use server-side rendering or dynamic rendering techniques to make sure content is available to Googlebot and users alike.
Conduct tests using Google’s URL Inspection Tool to see exactly how Googlebot views JavaScript content on your site. Troubleshoot any discrepancies to avoid missing out on valuable indexing.
Googlebot Crawl Budget Optimization
Managing your crawl budget is crucial, especially for larger websites. Google allocates each site a specific “crawl budget,” which limits how much of your site Googlebot can crawl in a set period. If this budget is mismanaged, high-priority pages might get missed, impacting your SEO.
Here’s how to ensure Googlebot spends its time on the pages that matter:
Key Crawl Budget Optimization Strategies
- Prioritize High-Value Pages: Identify pages that bring the most organic traffic or hold key content (e.g., product pages, blog posts). These should be easily accessible via internal links and included in your XML sitemap.
- Minimize Low-Value Pages: Prevent Googlebot from crawling low-value or duplicate pages. For example, tag archives or duplicate content variations. Use noindex or robots.txt directives strategically.
- Regularly Audit Internal Links: Internal linking plays a crucial role in guiding Googlebot. Ensure that valuable pages are linked from other high-traffic pages, and avoid broken or dead-end links.
- Reduce Redirect Chains: Excessive redirects slow Googlebot down. Check your site for any unnecessary 301 or 302 redirects and clean them up, especially for critical pages.
Crawl your website using a tool like Screaming Frog to identify orphan pages, excessive redirects, and unnecessary links. Addressing these will optimize crawl paths and make the most of your crawl budget.
Common Googlebot Issues and How to Troubleshoot Them
Even well-optimized websites face technical issues with Googlebot that can prevent effective crawling and indexing.
Here are the most common issues and quick ways to troubleshoot them to keep your SEO health in check:
1. Crawl Errors in Google Search Console
- Symptom: Pages aren’t getting indexed or appear as “Crawl errors” in Google Search Console.
- Solution: Regularly monitor Google Search Console’s “Coverage” report. Fix any identified 404s, 500s, or server errors, and use 301 redirects for broken links pointing to valuable pages.
2. Page Resources Blocked by Robots.txt
- Symptom: Critical assets (CSS, JavaScript) are being blocked from Googlebot, resulting in rendering issues.
- Solution: Use the “URL Inspection” tool in Google Search Console to see how Googlebot views your page. If essential files are blocked, adjust your robots.txt file to allow access, or remove “Disallow” directives where necessary.
3. Duplicate Content Confusion
- Symptom: Googlebot finds identical or very similar content on multiple pages, which may cause indexing issues.
- Solution: Use canonical tags to signal the preferred version of a page and prevent indexing of duplicates. Canonicalization is especially important for eCommerce sites with products available in multiple categories or variants.
4. JavaScript Not Rendering Properly
- Symptom: Content reliant on JavaScript doesn’t appear when tested in Google Search Console.
- Solution: If possible, use server-side rendering (SSR) or dynamic rendering for pages with JavaScript-dependent content. Also, check Google’s Mobile-Friendly Test to ensure the content loads properly on mobile.
Regularly review server logs to identify any unexpected Googlebot behavior or repetitive crawl patterns. This can reveal deeper issues like crawl loops or repeated attempts on blocked pages.
Conclusion
Optimizing your site for Googlebot isn’t just about satisfying a search engine—it’s about creating a website that’s efficient, accessible, and valuable for everyone who visits. By understanding how Googlebot crawls, indexing priorities, and ways to make your content stand out, you’re setting your website up for long-term growth in search rankings.
Remember, Google’s technology and algorithms will keep changing. The best approach is to regularly check your site’s performance, update valuable content, and keep an eye on any technical issues that might impact crawling and indexing. When you’re proactive with your SEO efforts, you’re not only making your site easier for Googlebot to navigate—you’re also building a better, more engaging experience for users.
Ultimately, a Googlebot-friendly website means a user-friendly website, and that’s what search engines—and your visitors—will always reward.
